Reckoning: Part 1 — The Landscape
Instead of an omnibus mega-post, this investigation into JavaScript-first frontend culture and how it broke US public services has been released in four parts. Other posts in the series:
When you live in the shadow of a slow-moving crisis, it's natural to tell people about it. At volume. Doubly so when engineers can cheaply and easily address the root causes with minor tweaks. As things worsen, it's also hard not to build empathy for Cassandra.
In late 2011, I moved to London, where the Chrome team was beginning to build Google's first "real" browser for Android.[1] The system default Android Browser had, up until that point, been based on the system WebView, locking its rate of progress to the glacial pace of device replacement.[2]
In a world where the Nexus 4's 2GB of RAM and 32-bit, 4-core CPU were the high-end, the memory savings the Android Browser achieved by reusing WebView code mattered immensely.[3] Those limits presented enormous challenges for Chromium's safer (but memory-hungry) multi-process sandboxing. Android wasn't just spicy Linux; it was an entirely new ballgame.
Even then, it was clear the iPhone wasn't a fluke. Mobile was clearly on track to be the dominant form-factor, and we needed to adapt. Fast.[4]
Browsers made that turn, and by 2014, we had made enough progress to consider how the web could participate in mobile's app-based model. This work culminated in 2015's introduction of PWAs and Push Notifications.
Disturbing patterns emerged as we worked with folks building on this new platform. A surprisingly high fraction of them brought slow, desktop-oriented JavaScript frameworks with them to the mobile web. These modern, mobile-first projects neither needed nor could afford the extra bloat frameworks included to paper over the problems of legacy desktop browsers. Web developers needed to adapt the way browser developers had, but consistently failed to hit the mark.
By 2016, frontend practice had fully lapsed into wish-thinking. Alarms were pulled, claxons sounded, but nothing changed.
It could not have come at a worse time.
By then, explosive growth at the low end was baked into the cake. Billions of feature-phone users had begun to trade up. Different brands endlessly reproduced 2016's mid-tier Androids under a dizzying array of names. The only constants were the middling specs and ever-cheaper prices. Specs that would set punters back $300 in 2016, sold for only $100 a few years later, opening up the internet to hundreds of millions along the way. The battle between the web and apps as the dominant platform was well and truly on.
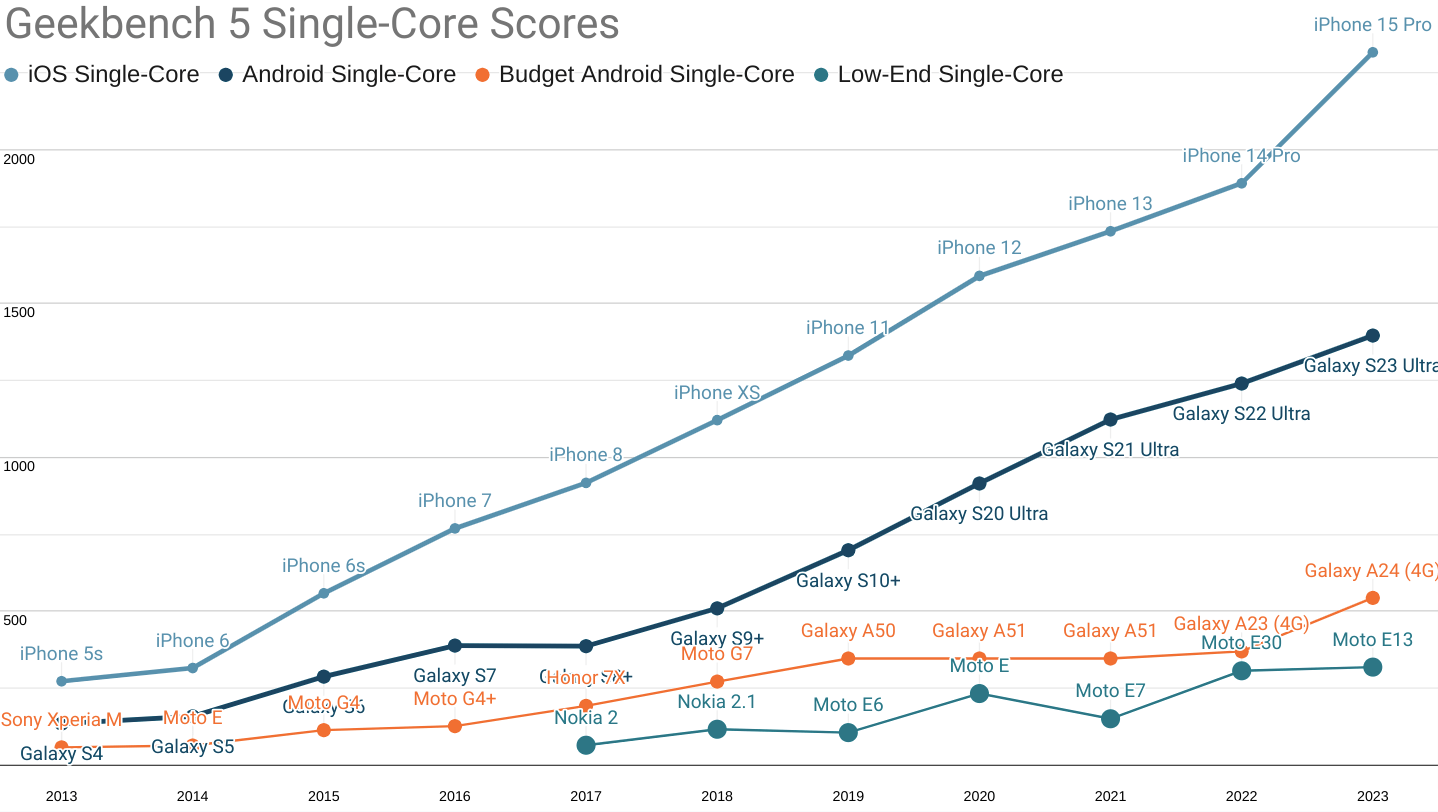
Geekbench 5 single-core scores for 'fastest iPhone', 'fastest Android', 'budget', and 'low-end' segments.
Nearly all growth in smartphone sales volume since the mid '10s occured in the 'budget' and 'low-end' categories.
But the low-end revolution barely registered in web development circles. Frontenders poured JavaScript into the mobile web at the same rate as desktop, destroying any hope of a good experience for folks on a budget.

As this blog has covered at length, median device specs were largely stagnant between 2014 and 2022. Meanwhile, web developers made sure the "i" in "iPhone" stood for "inequality."
Prices at the high end accelerated, yet average selling prices remained stuck between $300 and $350. The only way the emergence of the $1K phone didn't bump the average up was the explosive growth at the low end. To keep the average selling price at $325, three $100 low-end phones needed to sell for each $1K iPhone; which is exactly what happened.
And yet, the march of JavaScript-first, framework-centric dogma continued, no matter how incompatible it was with the new reality. Predictably, tools sold on the promise they would deliver "app-like experiences" did anything but.[5]
Billions of cheap phones that always have up-to-date browsers found their CPUs and networks clogged with bloated scripts designed to work around platform warts they don't have.
Environmental Factors #
In 2019, Code for America published the first national-level survey of online access to benefits programs, which are built and operated by each state. The follow-up 2023 study provides important new data on the spread of digital access to benefits services.
One valuable artefact from CFA's 2019 research is a post by Dustin Palmer, documenting the missed opportunity among many online benefits portals to design for the coming mobile-first reality that was already the status quo in the rest of the world.


Moving these systems online only reduces administrative burdens in a contingent sense; if portals fail to work well on phones, smartphone-dependent folks are predictably excluded:

But poor design isn't the only potential administrative burden for smartphone-dependent users.[6]
The networks and devices folks use to access public support aren't latest-generation or top-of-the-line. They're squarely in the tail of the device price, age, and network performance distributions. Those are the overlapping conditions where the consistently falsified assumptions of frontend's lost decade have played out disastrously.

It would be tragic if public sector services adopted the JavaScript-heavy stacks that frontend influencers have popularised. Framework-based, "full-stack" development is now the default in Silicon Valley, but should obviously be avoided in universal services. Unwieldy and expensive stacks that have caused agony in the commercial context could never be introduced to the public sector with any hope of success.
Right?
Next: Object Lesson: a look at California's digital benefits services.
Thanks to Marco Rogers, and Frances Berriman for their encouragement in making this piece a series and for their thoughtful feedback on drafts.
A "real browser", as the Chrome team understood the term circa 2012, included:
- Chromium's memory-hungry multi-process architecture which dramatically improved security and stability
- Winning JavaScript performance using our own V8 engine
- The Chromium network stack, including support for SPDY and experiments like WebRTC
- Updates that were not locked to OS versions
Of course, the Chrome team had wanted to build a proper mobile browser sooner, but Android was a paranoid fiefdom separate from Google's engineering culture and systems. And the Android team were intensely suspicious of the web, verging into outright hostility at times.
But internal Google teams kept hitting the limits of what the Android Browser could do, including Search. And when Search says "jump", the only workable response is "how high?"
WebKit-based though it was (as was Chrome), OS-locked features presented a familiar problem, one the Chrome team had solved with auto-update and Chrome Frame. A deal was eventually struck, and when Chrome for Android was delivered, the system WebView also became a Chromium-based, multi-process, sandboxed, auto-updating system. For most, that was job done.
This made a certain sort of sense. From the perspective of Google's upper management, Android's role was to put a search box in front of everyone. If letting Andy et al. play around with an unproven Java-based app model was the price, OK. If that didn't work, the web would still be there. If it did, then Google could go from accepting someone else's platform to having one it owned outright.[7] Win/win.
Anyone trying to suggest a more web-friendly path for Android got shut down hard. The Android team always had legitimate system health concerns that they could use as cudgels, and they weilded them with abandon.
The launch of PWAs in 2015 was an outcome Android saw coming a mile away and worked hard to prevent. But that's a story for another day. ↩︎
Android devices were already being spec'd with more RAM than contemporary iPhones, thanks to Dalvik's chonkyness. This, in turn, forced many OEMs to cut corners in other areas, including slower CPUs.
This effect has been a silent looming factor in the past decade's divergence in CPU performance between top-end Android and iPhones. Not only did Android OEMs have to pay a distinct profit margin to Qualcomm for their chips, but they also had to dip into the Bill Of Materials (BOM) budget to afford more memory to keep things working well, leaving less for the CPU.
Conversely, Apple's relative skimpiness on memory and burning desire to keep BOM costs low for parts it doesn't manufacture are reasons to oppose browser engine choice. If real browsers were allowed, end users might expect phones with decent specs. Apple keeps that in check, in part, by maximising code page reuse across browsers and apps that are forced to use the system WebView.
That might dig into margins ever so slightly, and we can't have that, can we? ↩︎
It took browsers that were originally architected in a desktop-only world many years to digest the radically different hardware that mobile evolved. Not only were CPU speeds and memory budgets cut dramatically — nevermind the need to port to ARM, including JS engine JITs that were heavily optimised for x86 — but networks suddenly became intermittent and variable-latency.
There were also upsides. Where GPUs had been rare on the desktop, every phone had a GPU. Mobile CPUs were slow enough that what had felt like a leisurely walk away from CPU-based rendering on desktop became an absolute necessity on phones. Similar stories played out across input devices, sensors, and storage.
It's no exaggeration to say that the transition to mobile force-evolved browsers in a compressed time frame. If only websites had made the same transition. ↩︎
Let's take a minute to unpack what the JavaScript framework claims of "app-like experiences" were meant to convey.
These were code words for more responsive UI, building on the Ajax momentum of the mid-naughties. Many boosters claimed this explicitly and built popular tools to support these specific architectures.
As we wander through the burning wreckage of public services that adopted these technologies, remember one thing: they were supposed to make UIs better. ↩︎
When confronted with nearly unusable results from tools sold on the idea that they make sites easier, better, and faster to use, many technologists offer the variants of "but at least it's online!" and "it's fast enough for most people". The most insipid version implies causality, constructing a strawman but-for defense; "but these sites might not have even been built without these frameworks."[9]
These points can be both true and immaterial at the same time. It isn't necessary for poor performance to entirely exclude folks at the margins for it to be a significant disincentive to accessing services.
We know this because it has been proven and continually reconfirmed in commercial and lab settings. ↩︎
The web is unattractive to every Big Tech company in a hurry, even the ones that owe their existence to it.
The web's joint custody arrangement rankles. The standards process is inscrutable and frustrating to PMs and engineering managers who have only ever had to build technology inside one company's walls. Playing on hard mode is unappealing to high-achievers who are used to running up the score.
And then there's the technical prejudice. The web's languages offend "serious" computer scientists. In the bullshit hierarchy of programming language snobbery, everyone looks down on JavaScript, HTML, and CSS (in that order).
The web's overwhelmingly successful languages present a paradox: for the comfort of the snob, they must simultaneously be unserious toys beneath the elevated palettes of "generalists" and also Gordian Knots too hard for anyone to possibly wield effectively. This dual posture justifies treating frontend as a less-than discipline, and browsers as anything but a serious application platform.
This isn't universal, but it is common, particularly in Google's C++/Java-pilled upper ranks.[8] Endless budgetary space for projects like the Android Framework, Dart, and Flutter were the result. ↩︎
Someday I'll write up the tale of how Google so thoroughly devalued frontend work that it couldn't even retain the unbelievably good web folks it hired in the mid-'00s. Their inevitable departures after years of being condescended to went hand-in-hand with an inability to hire replacements.
Suffice to say, by the mid '10s, things were bad. So bad an exec finally noticed. This created a bit of space to fix it. A team of volunteers answered the call, and for more than a year we met to rework recruiting processes and collateral, interview loop structures, interview questions, and promotion ladder criteria.
The hope was that folks who work in the cramped confines of someone else's computer could finally be recognised for their achievements. And for a few years, Google's frontends got markedly better.
I'm told the mean has reasserted itself. Prejudice is an insidious thing. ↩︎
The but-for defense for underperforming frontend frameworks requires us to ignore both the 20 years of web development practice that preceeded these tools and the higher OpEx and CapEx costs associated with React-based stacks.
Managers sometimes offer a hireability argument, suggesting they need to adopt these univerally more expensive and harder to operate tools because they need to be able to hire. This was always nonsense, but never more so than in 2024. Some of the best, most talented frontenders I know are looking for work and would leap at the chance to do good things in an organisation that puts user experience first.
Others sometimes offer the idea that it would be too hard to retrain their teams. Often, these are engineering groups comprised of folks who recently retrained from other stacks to the new React hotness or who graduated boot camps armed only with these tools. The idea that either cohort cannot learn anything else is as inane as it is self-limiting.
Frontenders can learn any framework and are constantly retraining just to stay on the treadmill. The idea that there are savings to be had in "following the herd" into Next.js or similar JS-first development cul-de-sacs has to meet an evidentiary burden that I have rarely seen teams clear.
Managers who want to avoid these messes have options.
First, they can crib Kellan's tests for new technologies. Extra points for digesting Glyph's thoughts on "innovation tokens."
Next, they should identify the critical user journeys in their products. Technology choices are always situated in product constraints, but until the critical user journeys are enunciated, the selection of any specific architecture is likely to be wrong.
Lastly, they should always run bakeoffs. Once critical user journeys are outlined and agreed, bakeoffs can provide teams with essential data about how different technology options will perform under those conditions. For frontend technologies, that means evaluating them under representative market conditions.
And yes, there's almost always time to do several small prototypes. It's a damn sight cheaper than the months (or years) of painful remediation work. I'm sick to death of having to hand-hold teams whose products are suffocating under unusably large piles of cruft, slowly nursing their code-bases back to something like health as their management belatedely learns the value of knowing their systems deeply.
Managers that do honest, user-focused bakeoffs for their frontend choices can avoid adding their teams to the dozens I've consulted with who adopted extremely popular, fundamentally inappropriate technologies that have had disasterous effects on their businesses and team velocity. Discarding popular stacks from consideration through evidence isn't a career risk; it's literally the reason to hire engineers and engineering leaders in the first place. ↩︎