The Market for Lemons
For most of the past decade, I have spent a considerable fraction of my professional life consulting with teams building on the web.
It is not going well.
Not only are new services being built to a self-defeatingly low UX and performance standard, existing experiences are pervasively re-developed on unspeakably slow, JS-taxed stacks. At a business level, this is a disaster, raising the question: "why are new teams buying into stacks that have failed so often before?"
In other words, "why is this market so inefficient?"
George Akerlof's most famous paper introduced economists to the idea that information asymmetries distort markets and reduce the quality of goods because sellers with more information can pass off low-quality products as more valuable than informed buyers appraise them to be. (PDF, summary)
Customers that can't assess the quality of products pay too much for poor quality goods, creating a disincentive for high-quality products to emerge while working against their success when they do. For many years, this effect has dominated the frontend technology market. Partisans for slow, complex frameworks have successfully marketed lemons as the hot new thing, despite the pervasive failures in their wake, crowding out higher-quality options in the process.[1]
These technologies were initially pitched on the back of "better user experiences", but have utterly failed to deliver on that promise outside of the high-management-maturity organisations in which they were born.[2] Transplanted into the wider web, these new stacks have proven to be expensive duds.
The complexity merchants knew their environments weren't typical, but sold their highly specialised tools to folks shopping for general purpose solutions anyway. They understood most sites lack latency budgeting, dedicated performance teams, hawkish management reviews, ship gates to prevent regressions, and end-to-end measurements of critical user journeys. They grasped that massive investment in controlling complexity is the only way to scale JS-driven frontends, but warned none of their customers.
They also knew that their choices were hard to replicate. Few can afford to build and maintain 3+ versions of a site ("desktop", "mobile", and "lite"), and vanishingly few web experiences feature long sessions and login-gated content.[3]
Armed with this knowledge, they kept the caveats to themselves.
What Did They Know And When Did They Know It? #
This information asymmetry persists; the worst actors still haven't levelled with their communities about what it takes to operate complex JS stacks at scale. They did not signpost the delicate balance of engineering constraints that allowed their products to adopt this new, slow, and complicated tech. Why? For the same reason used car dealers don't talk up average monthly repair costs.
The market for lemons depends on customers having less information than those selling shoddy products. Some who hyped these stacks early on were earnestly ignorant, which is forgivable when recognition of error leads to changes in behaviour. But that's not what the most popular frameworks of the last decade did.
As time passed, and the results continued to underwhelm, an initial lack of clarity was revealed to be intentional omission. These omissions have been material to both users and developers. Extensive evidence of these failures was provided directly to their marketeers, often by me. At some point (certainly by 2017) the omissions veered into intentional prevarication.
Faced with the dawning realisation that this tech mostly made things worse, not better, the JS-industrial-complex pulled an Exxon.
They could have copped to an honest error, admitted that these technologies require vast infrastructure to operate; that they are unscalable in the hands of all but the most sophisticated teams. They did the opposite, doubling down, breathlessly announcing vapourware year after year to forestall critical thinking about fundamental design flaws. They also worked behind the scenes to marginalise those who pointed out the disturbing results and extraordinary costs.
Credit where it's due, the complexity merchants have been incredibly effective in one regard: top-shelf marketing discipline.
Over the last ten years, they have worked overtime to make frontend an evidence-free zone. The hucksters knew that discussions about performance tradeoffs would not end with teams investing more in their technology, so boosterism and misdirection were aggressively substituted for evidence and debate. Like a curtain of Halon descending to put out the fire of engineering dialogue, they blanketed the discourse with toxic positivity. Those who dared speak up were branded "negative" and "haters", no matter how much data they lugged in tow.
Sandy Foundations #
Astonishingly, gobsmackingly effective bullshit, but nonsense nonetheless. There was a point to it, though. Playing for time allowed the bullshitters to punt introspection of the always-wrong assumptions they'd built their entire technical ediface on:
- CPUs get faster every year
[ narrator: they do not ] - Organisations can manage these complex stacks
[ narrator: they cannot ]
In time, these misapprehensions would become cursed articles of faith.
All of this was falsified by 2016, but nobody wanted to turn on the house lights while the JS party was in full swing. Not the developers being showered with shiny tools and boffo praise for replacing "legacy" HTML and CSS that performed fine. Not the scoundrels peddling foul JavaScript elixirs and potions. Not the managers that craved a check to write and a rewrite to take credit for in lieu of critical thinking about user needs and market research.
Consider the narrative Crazy Ivans that led to this point.

It's challenging to summarise a vast discourse over the span of a decade, particularly one as dense with jargon and acronyms as that which led to today's status quo of overpriced failure. These are not quotes, but vignettes of distinct epochs in our tortured journey:
- "Progressive Enhancement has failed! Multiple pages are slow and clunky!
SPAs are a better user experience, and managing state is a big problem on the client side. You'll need a tool to help structure that complexity when rendering on the client side, and our framework works at scale"
[ illustrative example ] - "Instead of waiting on the JavaScript that will absolutely deliver a superior SPA experience...someday...why not render on the server as well, so that there's something for the user to look at while they wait for our awesome and totally scalable JavaScript to collect its thoughts?"
[ an intro to "isomorphic javascript", a.k.a. "Server-Side Rendering", a.k.a. "SSR" ] - "SPAs are a better experience, but everyone knows you'll need to do all the work twice because SSR makes that better experience minimally usable. But even with SSR, you might be sending so much JS that things feel bad. So give us credit for a promise of vapourware for delay-loading parts of your JS."
[ impressive stage management ] - "SPAs are a better experience. SSR is vital because SPAs take a long time to start up, and you aren't using our vapourware to split your code effectively. As a result, the main thread is often locked up, which could be bad?
Anyway, this is totally your fault and not the predictable result of us failing to advise you about the controls and budgets we found necessary to scale JS in our environment. Regardless, we see that you lock up main threads for seconds when using our slow system, so in a few years we'll create a parallel scheduler that will break up the work transparently"
[ 2017's beautiful overview of a fated errand and 2018's breathless re-brand ] - "The scheduler isn't ready, but thanks for your patience; here's a new way to spell your component that introduces new timing issues but doesn't address the fact that our system is incredibly slow, built for browsers you no longer support, and that CPUs are not getting faster"
[ representative pitch ] - "Now that you're 'SSR'ing your SPA and have re-spelt all of your components, and given that the scheduler hasn't fixed things and CPUs haven't gotten faster, why not skip SPAs and settle for progressive enhancement of sections of a document?"
[ "islands", "server components", etc. ]
It's the Steamed Hams of technology pitches.
Like Chalmers, teams and managers often acquiesce to the contradictions embedded in the stacked rationalisations. Together, the community invented dozens of reasons to look the other way, from the theoretically plausible to the fully imaginary.
But even as the complexity merchant's well-intentioned victims meekly recite the koans of trickle-down UX — it can work this time, if only we try it hard enough! — the evidence mounts that "modern" web development is, in the main, an expensive failure.
The baroque and insular terminology of the in-group is a clue. It's functional purpose (outside of signaling) is to obscure furious plate spinning. The tech isn't working, but admitting as much would shrink the market for lemons.
You'd be forgiven for thinking the verbiage was designed obfuscate. Little comfort, then, that folks selling new approaches must now wade through waist-deep jargon excrement to argue for the next increment of complexity.
The most recent turn is as predictable as it is bilious. Today's most successful complexity merchants have never backed down, never apologised, and never come clean about what they knew about the level of expense involved in keeping SPA-oriented technologies in check. But they expect you'll follow them down the next dark alley anyway:

And why not? The industry has been down to clown for so long it's hard to get in the door if you aren't wearing a red nose.
The substitution of heroic developer narratives for user success happened imperceptibly. Admitting it was a mistake would embarrass the good and the great alike. Once the lemon sellers embed the data-light idea that improved "Developer Experience" ("DX") leads to better user outcomes, improving "DX" became and end unto itself. Many who knew better felt forced to play along.
The long lead time for falsifying trickle-down UX was a feature, not a bug; they don't need you to succeed, only to keep buying.
As marketing goes, the "DX" bait-and-switch is brilliant, but the tech isn't delivering for anyone but developers.[4] The highest goal of the complexity merchants is to put brands on showcase microsites and to make acqui-hiring failing startups easier. Performance and success of the resulting products is merely a nice-to-have.
Denouement #
You'd think there would be data, that we would be awash in case studies and blog posts attributing product success to adoption of SPAs and heavy frameworks in an incontrovertable way.
And yet, after more than a decade of JS hot air, the framework-centric pitch is still phrased in speculative terms because there's no there there. The complexity merchants can't cop to the fact that management competence and lower complexity — not baroque technology — are determinative of product and end-user success.
The simmering, widespread failure of SPA-premised approaches has belatedly forced the JS colporteurs to adapt their pitches. In each iteration, they must accept a smaller rhetorical lane to explain why this stack is still the future.
The excuses are running out.
At long last, the journey has culminated with the rollout of Core Web Vitals. It finally provides an objective quality measurement that prospective customers can use to assess frontend architectures.
It's no coincidence the final turn away from the SPA justification has happened just as buyers can see a linkage between the stacks they've bought and the monetary outcomes they already value; namely SEO. The objective buyer, circa 2023, will understand heavy JS stacks as a regrettable legacy, one that teams who have hollowed out their HTML and CSS skill bases will pay for dearly in years to come.
No doubt, many folks who know their JS-first stacks are slow will do as Akerlof predicts, and obfuscate for as long as possible. The market for lemons is, indeed, mostly a resale market, and the excesses of our lost decade will not be flushed from the ecosystem quickly. Beware tools pitching "100 on Lighthouse" without checking the real-world Core Web Vitals results.
Shrinkage #
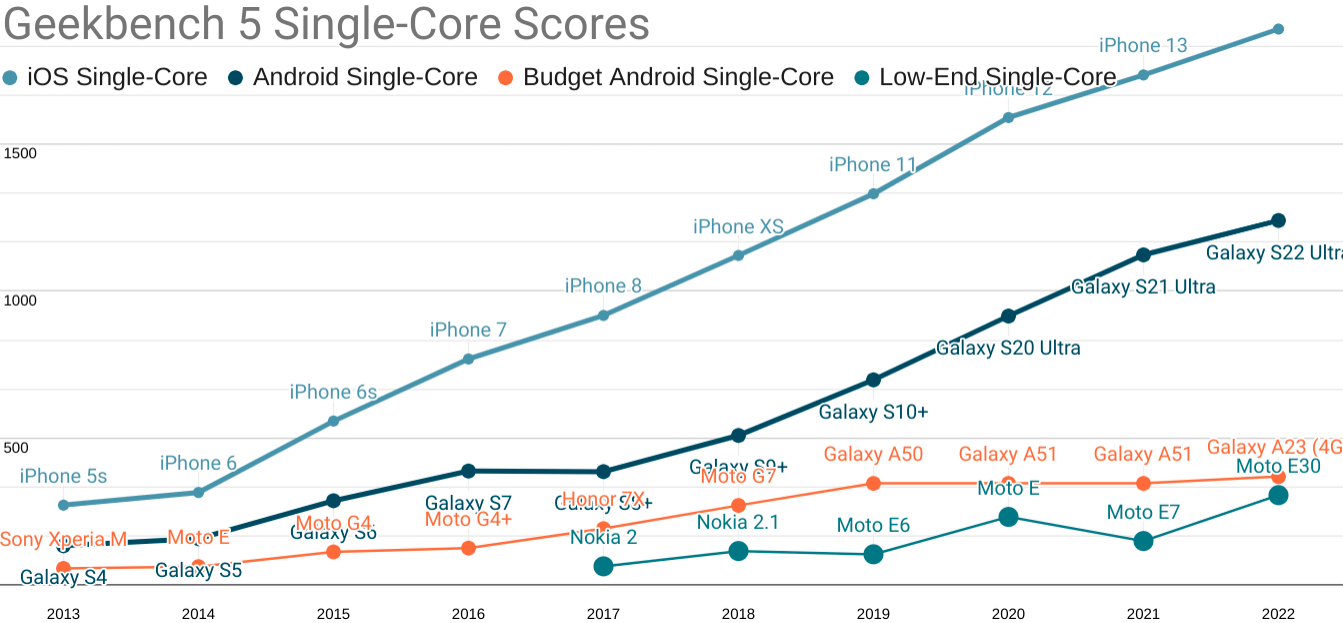
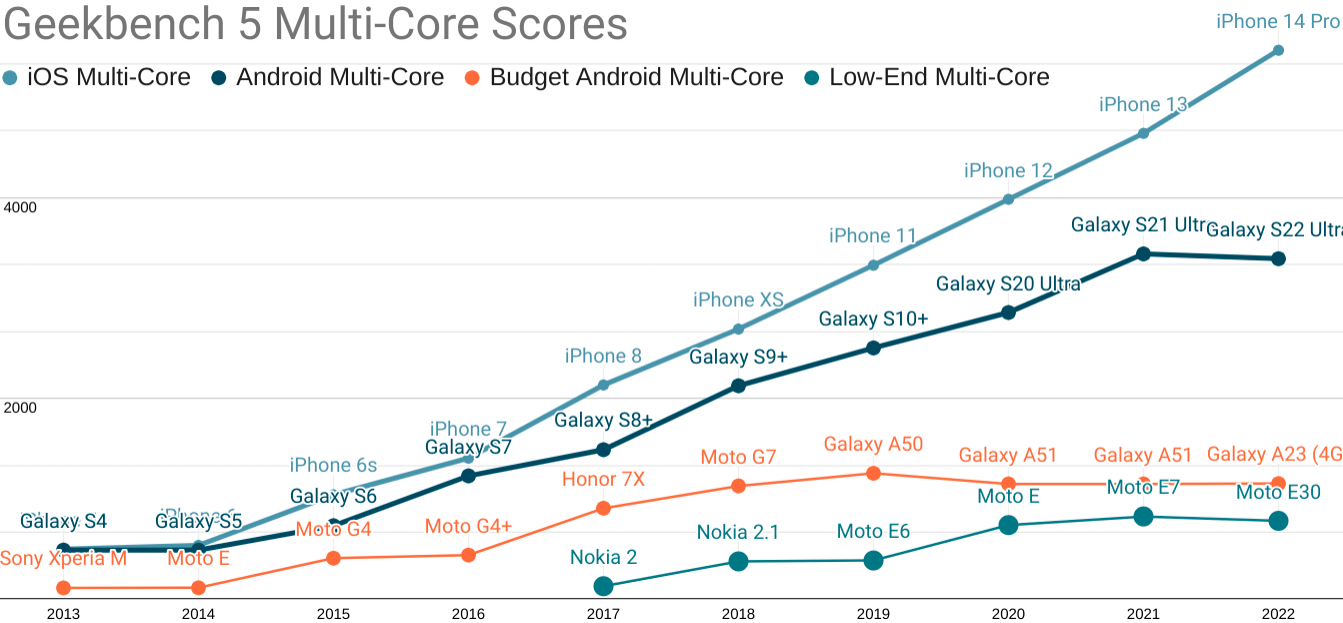
A subtle aspect of Akerlof's theory is that markets in which lemons dominate eventually shrink. I've warned for years that the mobile web is under threat from within, and the depressing data I've cited about users moving to apps and away from terrible web experiences is in complete alignment with the theory.
When websites feel like worse experiences to the folks who write the checks, why should anyone expect them to spend a lot on them? And when websites stop being where accurate information and useful services are, will anyone still believe there's a future in web development?
The lost decade we've suffered at the hands of lemon purveyors isn't just a local product travesty; it's also an ecosystem-level risk. Forget AI putting web developers out of jobs; JS-heavy web stacks have been shrinking the future market for your services for years.
Adam Smith's invisible hand — the idea that free markets lead to efficiency as if guided by unseen forces — is invisible, at least in part, because it is not there.
But dreams die hard.
I'm already hearing laments from folks who have been responsible citizens of framework-landia lo these many years. Oppressed as they were by the lemon vendors, they worry about babies being throw out with the bathwater, and I empathise. But for the sake of users, and for the new opportunities for the web that will open up when experiences finally improve, I say "chuck those tubs".
Chuck 'em hard, and post the photos of the unrepentant bastards that sold this nonsense behind the cash register.

We lost a decade to smooth talkers and hollow marketeering; folks who failed the most basic test of intellectual honesty: signposting known unknowns. Instead of engaging honestly with the emerging evidence, they sold lemons and shrunk the market for better solutions. Furiously playing catch-up to stay one step ahead of market rejection, frontend's anguished, belated return to quality has been hindered at every step by those who would stand to lose if their false premises and hollow promises were to be fully re-evaluated.
Toxic mimicry and recalcitrant ignorance must not be rewarded.
Vendor's random walk through frontend choices may eventually lead them to be right twice a day, but that's not a reason to keep following their lead. No, we need to move our attention back to the folks that have been right all along. The people who never gave up on semantic markup, CSS, and progressive enhancement for most sites. The people who, when slinging JS, have treated it as special occasion food. The tools and communities whose culture puts the user ahead of the developer and hold evidence of doing better for users in the highest regard.[1:1]
It's not healing, and it won't be enough to nurse the web back to health, but tossing the Vercels and the Facebooks out of polite conversation is, at least, a start.
Deepest thanks to Bruce Lawson, Heydon Pickering, Frances Berriman, and Taylor Hunt for their thoughtful feedback on drafts of this post.
You wouldn't know it from today's frontend discourse, but the modern era has never been without high-quality alternatives to React, Angular, Ember, and other legacy desktop-era frameworks.
In a bazaar dominated by lemon vendors, many tools and communities have been respectful of today's mostly-mobile users at the expense of their own marketability. These are today's honest brokers and they deserve your attention far more than whatever solution to a problem created by React that the React community is on about this week.
This has included JS frameworks with an emphasis on speed and low overhead vs. cadillac comfort of first-class IE8 support:
It's possible to make slow sites with any of these tools, but the ethos of these communities is that what's good for users is essential, and what's good for developers is nice-to-have — even as they compete furiously for developer attention. This uncompromising focus on real quality is what has been muffled by the blanket the complexity merchants have thrown over today's frontend discourse.
Similarly, the SPA orthodoxy that precipitated the market for frontend lemons has been challenged both by the continued success of "legacy" tools like WordPress, as well as a new crop of HTML-first systems that provide JS-friendly authoring but output that's largely HTML and CSS:
The key thing about the tools that work more often than not is that they start with simple output. The difficulty in managing what you've explicitly added based on need, vs. what you've been bequeathed by an inscrutable Rube Goldberg-esque framework, is an order of magnitude in difference. Teams that adopt tools with simpler default output start with simpler problems that tend to have better-understood solutions. ↩︎ ↩︎
Organisations that manage their systems (not the other way around) can succeed with any set of tools. They might pick some elegant ones and some awkward ones, but the sine qua non of their success isn't what they pick up, it's how they hold it.
Recall that Facebook became a multi-billion dollar, globe-striding colossus using PHP and C++.
The differences between FB and your applications are likely legion. This is why it's fundamentally lazy and wrong for TLs and PMs to accept any sort of argument along the lines of "X scales, FB uses it".
Pigs can fly; it's only matter of how much force you apply — but if you aren't willing to fund creation of a large enough trebuchet, it's unlikley that porcine UI will take wing in your organisation. ↩︎
I hinted last year at and under-developed model for how we can evolve our discussion around web performance to take account of the larger factors that distinguish different kinds of sites.
While it doesn't account for many corner-cases, and is insufficient on its own to describe multi-modal experiences like WordPress (a content-producing editor for a small fraction of important users vs. shallow content-consumption reader experience for most), I wind up thinking about the total latency incurred in a user's session divided by the number of interactions. This raises a follow-on question: what's an interaction? Elsewhere, I've defined it as "turns through the interaction loop", but can be more easily described as "taps or clicks that involve your code doing work". This helpfully excludes scrolling, but includes navigations.
ANYWAY, all of this nets out a session-depth weighted intuition about when and where heavyweight frameworks make sense to load up-front:

Sites with shorter average sessions can afford less JS up-front. Social media sites that gate content behind a login (and can use the login process to pre-load bundles), and which have tons of data about session depth — not to mention ML-based per-user bundling, staffed performance teams, ship gates to prevent regressions, and the funding to build and maintain at least 3 different versions of the site — can afford to make fundamentally different choices about how much to load up-front and for which users.
The rest of us, trying to serve all users from a single codebase, need to prefer conservative choices that align with our management capacity to keep complexity in check. ↩︎
The "DX" fixation hasn't even worked for developers, if we're being honest. Teams I work with suffer eye-watering build times, shockingly poor code velocity, mysterious performance cliffs, and some poor sod stuck in a broom closet that nobody bothers, lest the webs stop packing.
And yet, these same teams are happy to tell me they couldn't live without the new ball-and-chain.
One group, after weeks of debugging a particularly gnarly set of issues brought on by their preposterously inefficient "CSS-in-JS" solution, combined with React's penchant for terrible data flow management, actually said to me that they were so glad they'd moved everything to hooks because it was "so much cleaner" and that "CSS-in-JS" was great because "now they could reason about it"; nevermind the weeks they'd just lost to the combination of dirtier callstacks and harder to reason about runtime implications of heisenbug styling.
Nothing about the lived experience of web development has meaningfully improved, except perhaps for TypeScript adding structure to large codebases. And yet, here we are. Celebrating failure as success while parroting narratives about developer productivity that have no data to back them up.
Sunk-cost fallacy rules all we survey. ↩︎