VCs planted the flag with sufficient force and cash (of dubious origin) to cause even sceptical outlets to report on it as though "web3" is a real thing.
Which it is not — at least not in any useful sense:
The NFT token you bought either points to a URL on the internet, or an IPFS hash. In most circumstances it references an IPFS gateway on the internet run by the startup you bought the NFT from.
Oh, and that URL is not the media. That URL is a JSON metadata file
What has perhaps earned proponents of JSON-files-that-point-to-JPGs less scorn, however, are attempts to affiliate their technologies with the web when, in fact, the two are technically unrelated by design. The politics of blockchain proponents have led them to explicitly reject the foundational protocols and technical underpinnings of the web. "web3" tech can't be an evolution of the web because it was designed to stand apart.
What is the web proper?
Cribbing from Dieter Bohn's definition, the web is the set of HTML documents (and subresources they reference) currently reachable via links.
To be on the web is to be linked to and linked from — very literally, connected by edges in a great graph. And the core of that connection? DNS, the "Domain Name System" that allows servers running at opaque and forgettable IP addresses to be found at friendlier names, like infrequently.org.
DNS underpins URLs. URLs and links make the web possible. Without these indirections, the web would never have escaped the lab.
These systems matter because the web is for humans, and humans have feeble wetware that doesn't operate naturally on long strings of semi-random numbers and characters. This matters to claims of decentralisation because, underneath DNS, the systems that delivered this very page you're reading to your screen are, in fact, distributed and decentralised.
Naming is centralising.
"web3" partisans often cast a return to nameless, unmemorable addresses as a revolution when their systems rely on either the same centralising mechanisms or seek to re-create them under new (less transparent, equally rent-seeking) management. As a technical matter, browsers are capable of implementing content-addressed networking, thanks to Web Packages, without doing violence to the web's gaurantees of safety in the process. Still, it turns out demand for services of this sort hasn't been great, in part, because of legitimate privacy concerns.
"web3" proponents variously dismiss and (sometimes) claim to solve privacy concerns, but the technical reality is less hospitable: content-addressed data must be either fully public or rely on obscurity.
Accessing "web3"-hosted files is less private because the architecture of decentralisation choosen by "web3" systems eschews mechanisms that build trust in the transport layer. A fully public, immutable ledger of content, offered by servers you don't control and can't attribute or verify, over links you can't trust, is hardly a recipe for privacy. One could imagine blockchain-based solutions to some of these problems, but this isn't the focus of "web3" boosters today.
Without DNS-backed systems like TLS there's little guarantee that content consumption will prevent tracking by parties even more unknowable than in the "web 2.0" mess that "web3" advocates decry.
Hanlon's Razor demands we treat these errors and omissions as sincere, if misguided.
What's less excusable is an appropriation of the term "web" concerning (but not limited to):
NFTs
Cryptocurrencies
Blockchain protocols
Crypto project "standards"
Despite forceful assertions that these systems represent the next evolution of "the web", they technically have no connection to it.
This takes doing! The web is vastly capable, and browsers today are in the business of providing access to nearly every significant subsystem of modern commodity computers. If "web3" were truly an evolution of the web, surely there would be some technical linkage... and yet.
Having rejected the foundational protocols of the web, these systems sail a parallel plane, connecting only over "bridges" and "gateways" which, in turn, give those who run the gateways incredible centralised power.
Browsers aren't going to engineer this stuff into the web's liberally licensed core because the cryptocurrency community hasn't done the necessary licensing work. Intricate toil is required to make concrete proposals that might close these gaps and demonstrate competent governance, and some of it is possible. But the community waving the red shirt of "web3" isn't showing up and isn't doing that work.
What this amounts to, then, is web-washing.
The term "web3" is a transparent attempt to associate technologies diametrically opposed to the web with its success; an effort to launder the reputation of systems that have most effectively served as vehicles for money laundering, fraud, and the acceleration of ransomware using the good name of a system that I help maintain.
Perhaps this play to appropriate the value of the web is what it smells like: a desperate move by bag-holders to lure in a new tranche of suckers, allowing them to clear speculative positions. Or perhaps it's honest confusion. Technically speaking, whatever it is, it isn't the web or any iteration of it.
The worst versions of this stuff use profligate, world-burning designs that represent a threat to the species. There's work happening in some communities to address those challenges, and that's good (if overdue). Even so, if every technology jockeying for a spot under the "web3" banner evolves beyond proof-of-work blockchains, these systems will still not be part of the web because they were designed not to be.
That could change. Durable links could be forged, but I see little work in that direction today. For instance, systems like IPFS could be made to host Web Packages which would (at least for public content) create a web-centric reason to integrate the protocol into browsers. Until that sort of work is done, folks using the "web3" coinage unironically are either grifters or dupes. Have pity, but don't let this nonsense slide.
"web3" ain't the web, and the VCs talking their own book don't get the last word, no matter how much dirty money they throw at it.
Update (September 25th, 2021): Commenters appear confused about Apple's many options to ensure safety in a world of true browser competition, JITs and all. This post has been expanded to more clearly enunciate a few of these alternatives.
How does Apple justify such a policy? Particularly since last winter, when it finally (ham-fistedly, eventually) became possible to set a browser other than Safari as the default?
Two categories of argument are worth highlighting: those offered by Apple and claims made by others in Apple's defence.[1]
Experts tend to treat Apple's arguments with disdain, but this skepticism is expressed in technical terms that can obscure deeper issues. Apple's response to the U.S. House Antitrust Subcommittee includes its fullest response and it provides a helpful, less-technical framing to discuss how browser engine choice relates to power over software distribution:
4. Does Apple restrict, in any way, the ability of competing web browsers to deploy their own web browsing engines when running on Apple's operating system? If yes, please describe any restrictions that Apple imposes and all the reasons for doing so. If no, please explain why not.
All iOS apps that browse the web are required to use "the appropriate WebKit framework and WebKit Javascript" pursuant to Section 2.5.6 of the App Store Review Guidelines
<https://developer.apple.com/app-store/review/guidelines/#software-requirements>.
The purpose of this rule is to protect user privacy and security. Nefarious websites have analysed other web browser engines and found flaws that have not been disclosed, and exploit those flaws when a user goes to a particular website to silently violate user privacy or security. This presents an acute danger to users, considering the vast amount of private and sensitive data that is typically accessed on a mobile device.
By requiring apps to use WebKit, Apple can rapidly and accurately address exploits across our entire user base and most effectively secure their privacy and security. Also, allowing other web browser engines could put users at risk if developers abandon their apps or fail to address a security flaw quickly. By requiring use of WebKit, Apple can provide security updates to all our users quickly and accurately, no matter which browser they decide to download from the App Store.
WebKit is an open-source web engine that allows Apple to enable improvements contributed by third parties. Instead of having to supply an entirely separate browser engine (with the significant privacy and security issues this creates), third parties can contribute relevant changes to the WebKit project for incorporation into the WebKit engine.
Let's address these claims from most easily falsified to most contested.
The open source nature of WebKit is indisputable as a legal technicality. Anyone who cares to download and fork the code can do so. To the extent they are both skilled in browser construction and have the freedom to distribute modified binaries, WebKit's source code can serve as the basis for new engines. Anyone can fork WebKit and improve it, but they cannot ship enhancements to iOS users of their products.
Apple asserts this is fine becase WebKit's openness extends to open governance regarding feature additions. It must know this is misleading.
Presumably, Apple's counsel included this specious filigree to distract from the reality that Apple rarely accepts outside changes that push the state of the art forward. Here I speak from experience.
From 2008 to 2013, the Chromium project was based on WebKit, and a growing team of Chrome engineers began to contribute heavily "upstream." I helped lead the team that developed Web Components. Our difficulty in trying to develop these features in WebKit cannot be overstated. The eventual Blink fork was precipitated by an insurmountable difficulty in doing precisely what Apple suggested to Congress: contributing new features to WebKit.
The differing near-term objectives of browser teams often make potential additions contentious, and only competition has been shown to reliably drive consensus. Every team has more than enough to do, and time spent even considering new features can be seen as a distraction. Project owners fiercely guard the integrity of their codebases. Until and unless they become convinced of the utility of a feature, "no" is the usual response. If there is no competition to force the issue, it can also be the final answer.
Browser engines are large projects, necessitating governance through senior engineer code review. There tend to be very few experts empowered to do reviews in each area relative to number of engineers contributing code.
It's inevitable that managers will communicate disinterest in continuing collaboration if they find their most senior engineers spending a great deal of time reviewing code for features they have no interest in and will disable ("flag off") in their own products[2]. The pace of code reviews needed to finish a feature in this state can taper off or dry up completely, frustrating collaborators on both sides.
When browsers provide their own engines (an "integrated browser"), then it's possible to disagree in standards venues, return to one's corner, and deliver their best design to developers (responsibly, hopefully). Developers can then provide feedback and lobby other vendors to adopt (or re-design) them. This process can be messy and slow, but it never creates a political blockage for developing new capabilities for the web.
WebKit, by contrast, has in recent years gone so far as to publicly, pre-emptively "decline to implement" a veritable truckload features that some vendors feel are essential and would be willing to ship in their products.
The signal to parties who might contribute code for these features could scarcely be clearer: your patch is unlikely to be accepted into WebKit.
Suppose by some miracle a "controversial" feature is merged into WebKit. This is no gaurantee that iOS browsers will gain access to it. Features in this state have lingered behind flags for years, ensuring they are not available in either Safari or competing iOS browsers.
When priority disagreements inevitably arise, competing iOS browsers cannot reliably demonstrate a feature is safe or well received by web developers by contributing to WebKit. Potential sponsors of this work won't dare the expense of an attempt. Apple's opacity and history of challenging collaboration have done more than enough to discourage ambitious participants.
Other mechanisms for extending features of third party browsers may be possible (in some areas, with low fidelity; more on that below), but contributions to WebKit are not a viable path for a majority of potential additions.
It is shocking, but unsurprising, that Apple felt compelled to mislead Congress on these points. The facts are not in their favour, but few legislative staffers have enough context to see through debates about browser internals.
The most convincing argument in Apple's 2019 response to the U.S. House Judiciary Committee is rooted in security. Apple argues it bans other engines from iOS because:
Nefarious websites have analysed other web browser engines and found flaws that have not been disclosed, and exploit those flaws when a user goes to a particular website to silently violate user privacy or security.
As a result of this threat landscape, responsible browser vendors work to put untrusted code (everything downloaded from the web) in "sandboxes"; restricted execution environments that are given fewer privileges than regular programs. Modern browsers layer protections on top of OS-level sandboxes, bolstering the default configuration with further limits on "renderer" processes.
The incredibly powerful devices Apple sells provide more than enough resources to raise such software defences, yet iOS users are years behind in recieving them and can't access them by switching browser. Apple's under-investment in security combine with its uniquely anti-competitive polices to ensure these gaps cannot be filled, no matter how contientious iOS users are about their digital hygiene.
Leading browsers are also adopting more robust processes for closing the "patch gap". Since all engines contain latent security bugs, precautions to insulate users from partial failure (e.g., sandboxing), and the velocity with which fixes reach end-user devices are paramount in determining the security posture of modern browsers. Apple's rather larger patch gap serves as an argument in favour of engine choice, all things equal. Cupertino's industry-lagging pace in adding additional layers of defence do not inspire confidence, either.
This brings us to the final link in the chain of structural security mitigations: the speed of delivering updates to end-users. Issues being fixed in the source code of an engine's project has no impact on its own; only when those fixes are rolled into new binaries and those binaries are delivered to user's devices do patches become fixes.
Apple's reply hints at the way its model for delivering fixes differs from all of its competitors:
[...] By requiring apps to use WebKit, Apple can rapidly and accurately address exploits across our entire user base and most effectively secure their privacy and security.
[...]
By requiring use of WebKit, Apple can provide security updates to all our users quickly and accurately, no matter which browser they decide to download from the App Store.
Aside from Chrome OS (and not for much longer), I'm aware of no modern browser that continues the medieval practice of requiring users download and install updates to their Operating System to apply browser patches. Lest Chrome OS's status quo seem a defence of iOS, know that the cost to end-users of these updates in terms of time and effort is night-and-day, thanks to near-instant, transparent updates on restart. If only my (significantly faster) iOS devices updated this transparently and quickly!
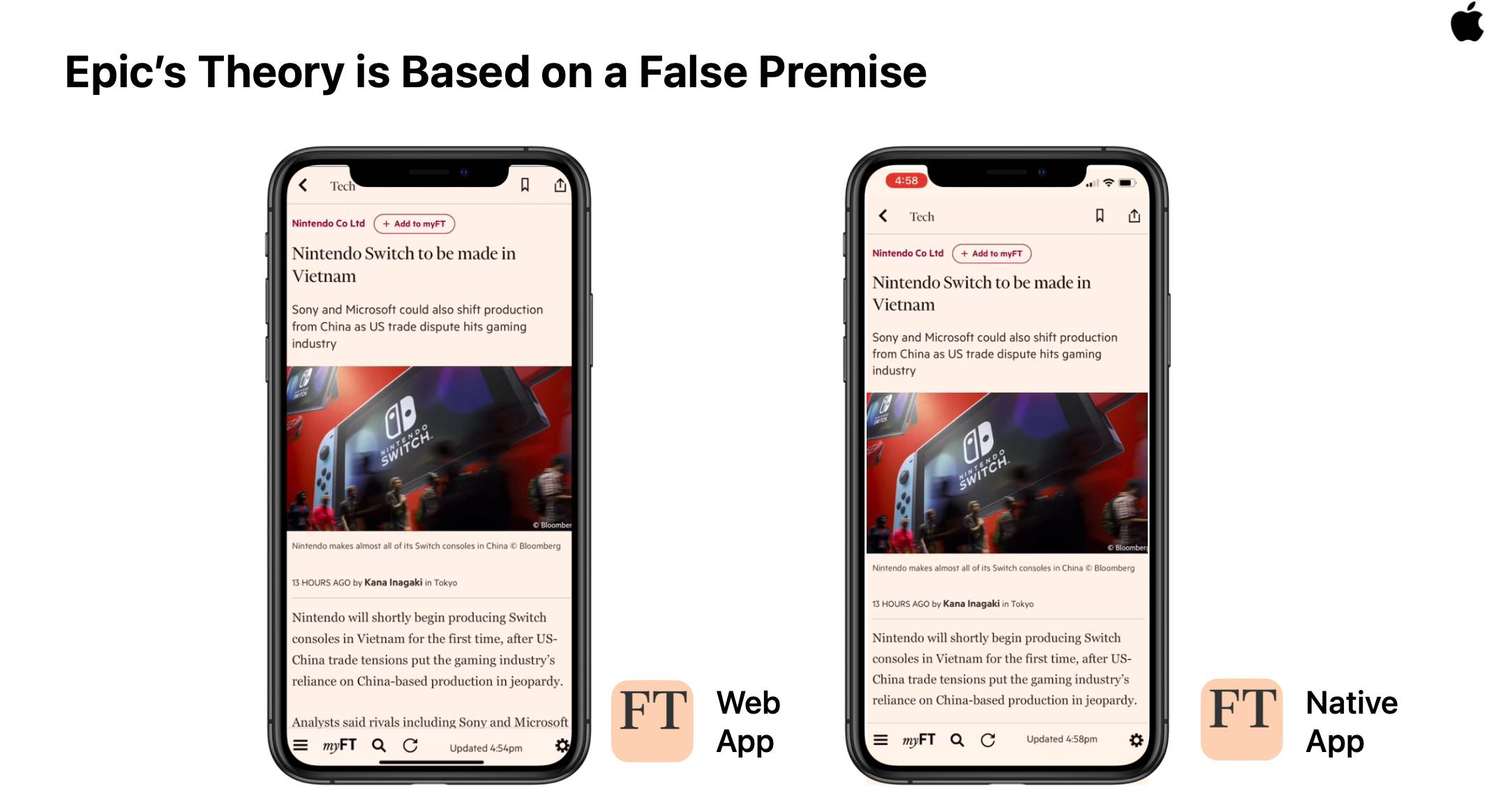
Why Is This Still A Thing?
Unlike browsers on every other major OS, updates to Safari are a painful affair, often requiring system reboots that take tens of minutes, providing multiple chances to re-take this photo.
Lower-friction updates lead to faster patch application, keeping users safer, and Chrome OS is miles ahead of iOS in this regard.
All other browsers update "out of band" from the OS, including the WebView system component on Android. The result is, that for users with equivalent connectivity and disk space, out-of-band patches are installed on the devices significantly faster.
This makes intuitive sense: iOS update downloads are large and installing them can disrupt using a device for as much as a half hour. Users are understandably hesitant to incur these interruptions. Browser updates delivered out-of-band can be smaller and faster to apply, often without explicit user intervention. In many cases, simply restarting the browser delivers improved security updates.
Differences in uptake rates matter because it's only by updating a program on the user's devices that fixes can begin to protect users. iOS's high friction engine updates are a double strike against its security posture; albeit ones Cupertino has attempted to spin as a positive.
The philosophical differences underlying software update mechanisms run deep. All other projects have learned through long experience to treat operating systems as soft targets that must be defended by the browser, rather than as the ultimate source of user defence. To the extent that the OS is trustworthy, that's a "nice to have" property that can add additional protection, but it is not treated as a fundamental protection in and of itself. Browser engineers outside the WebKit and Safari projects are habituated to thinking of OS components as systems not designed for handling unsafe third-party input. Mediating layers are therefore built to insulate the OS from malicious sites.
Apple, by contrast, tends to rely on OS components directly, leaning on fixes within the OS to repair issues which other projects can patch at a higher level. Apple's insistence on treating the OS as a single, hermetic unit slows the pace of fixes reaching users, and results in reduced flexibility in delivering features to web developers. While iOS has decent baseline protections, being unable to layer on extra levels of security is a poor trade.
This arrangement is, however, maximally efficient for Apple in terms of staffing. But is HR cost efficiency for Apple the most important feature of a web engine? And shouldn't users be able to choose engines that are willing to spend more on engineering to prevent latent OS issues from becoming security problems? By maintaining a thin artifice of perfect security, Apple's iOS monoculture renders itself brittle in the face of new threats, leaving users without the benefits of the layered paranoia that the most secure browsers running on the best OSes can provide.[3] As we'll see in a moment, Apple's claim to keep users safe when using alternative browsers by fusing engine updates to the OS is, at best, contested.
Instead of raising the security floor, Apple has set a cap while breeding a monoculture that ensures all iOS browsers are vulnerable to identical attacks, no matter whose icon is on the home screen.
Preventable insecurity, iOS be thy name.
Update: In February 2022, Google's Project Zero posted a report on the metrics they track regarding product bug and patch rates. This included a section on browsers, which included the following — incredibly damning — chart:
To quote the post: 'WebKit is the outlier in this analysis, with the longest number of days to release a patch at 73 days.'
Given Apple's response to Congress, it seems Cupertino is unfamiliar with the way iOS browsers other than Safari are constructed. Because it forbids integrated browsers, developers have no choice but to use Apple's own APIs to construct message-passing mechanisms between the privileged Browser Process and Renderer Processes sandboxed by Apple's WebKit framework.
These message-passing systems make it possible for WebKit-based browsers to add a limited subset of new features, even within the confines of Apple's WebKit binary. With this freedom comes the exact sort of liabilities that Apple insists it protects users from by fixing the full set of features firmly at the trailing edge.
To drive the point home: alternative browsers can include security issues every bit as severe as those Apple nominally guards against because of the side-channels provided by Apple's own WebKit framework. Any capability or data entrusted to the browser process can, in theory, be put at risk by these additional features.
More troublingly, these features are built in a way that is different to the mechanisms used by browser teams on every other platform. Any browser that delivers a feature to other platforms, then tries to bring it to iOS through script extensions, has doubled the security analysis and attack surface area.
None of this is theoretical; needing to re-develop features through a straw, using less-secure, more poorly tested and analyzed mechanisms, has led to serious security issues in alternative iOS browsers. Apple's policy, far from insulating responsible WebKit browsers from security issues, is a veritable bug farm for the projects wrenched between the impoverished feature set of Apple's WebKit and the features they can securely deliver with high fidelity on every other platform.
This is, of course, a serious problem for Apple's argument as to why it should be exclusively responsible for delivering updates to browser engines on iOS.
Apple cautions against poor browser vendor behaviour in its response, and it deserves special mention:
[...] Also, allowing other web browser engines could put users at risk if developers abandon their apps or fail to address a security flaw quickly.
Ignoring the extent to which WebKit represents precisely this scenario to vendors who would give favoured appendages to deliver stronger protections to their users on iOS, the justification for Apple's security ceiling has a (very weak) point: browsers are a serious business, and doing a poor job has bad consequences. One must wonder, of course, how Apple treats applications with persistent security issues that aren't browsers. Are they un-published from the App Store? And if so, isn't that a reasonable precedent here?
Whatever the precedent, Apple is absolutely correct that browsers shouldn't be distributed without commitments to maintenance, and that vendors who fail to keep the pace with security patches shouldn't be allowed to degrade the security posture of end-users. Fortunately, these are terms that nearly every reputable browser developer can easily agree to.
Indeed, reputable browser vendors would very likely be willing to sign up to terms that only allow use of the (currently proprietary and private) APIs that Apple uses to create sandboxed renderer processes for WebKit if their patch and CVE-fix rates matched some reasonable baseline. Apple's recently-added Browser Entitlement provides a perfect way to further contain the risk: only browsers that can be set as the system default could be allowed to bring alternative engines. Such a solution preserves Apple's floor on abandonware and embedded WebViews without capping the potential for improved experiences.
There are many options for managing the clearly-identifiable case of abandonware browsers, assuming Apple managers are genuinely interested solutions rather than sandbagging the pace of browser progress. Setting high standards has broad support.
The history of this unstated policy is long, winding, and less enlightening than a description of the status quo:
All major browser engines support both a JIT "fast path" for running JavaScript, as well as an "interpreted mode" that trades a JITs large gains in execution speed for faster start-up and lower memory use.
Safari on iOS had JIT for many years, whereas competing browsers were prevented from approaching similar levels of performance. More recently, WebView browsers on iOS have been able to take advantage of WebKit's JIT-ing JavaScript engine, but are prevented from bringing their own.
In addition to WebKit's lack of important JavaScript engine features (e.g. WASM Threads) and protections (Site Isolation), Apple's policy makes little sense on its visible merits.
Obviously, the speed delivered by JITs is important in browser competition, but it's also a fallacy to assume competitors wouldn't prefer the freedom to improve the performance, compatibility, and capabilities of the rest of their engines because they might not be able to JIT JavaScript. Every modern browser can run without a JIT, and many would prefer that to being confined to Apple's trailing-edge, low-quality engine.
So what does the prohibition on JITs actually accomplish?
As far as I can tell, disallowing other engines and their JIT-ing JavaScript runtimes mints Apple (but not users) two key benefits:
Allowing other engines would mean providing access to the currently-private APIs that allow the creation of sandboxed subprocesses.[4]
Blessing Safari as the only app allowed to mint sandboxed subprocesses, while preventing other from doing so, is clearly unfair. This one-sided situation has persisted because the details of sandboxing and process creation have been obscured by a blanket prohibition on alternative engines. Should Apple choose (or be required) to allow higher-quality engines, this private API should surely be made public, even if it's restricted to browsers.
Similarly, skimping on RAM in thousand-dollar phones seems a weak reason to deny users access to faster, safer browsers. The Chromium project has a history of strengthening the default sandboxes provided by OSes (including Apple's), and would no doubt love the try its hand at improving Apple's security floor qua ceiling.
The relative problems with JITs — very much including Apple's — are, if anything, an argument for opening the field to vendors who will to put in the work Apple has not to protect users. If the net result is that Cupertino sells safer devices while accepting a slightly lower margin (or an even more eye-watering price) on its super-premium devices, what's the harm? And isn't that something the market should sort out?
High-modernism may mean never having to admit you're wrong, but it doesn't keep one from errors that functional markets would discipline. You do learn about them, but at the greatest of delays.
Apple may genuinely believe it is improving security by preventing other engines, not just padding its bottom line. For instance, beyond the abandonware problem, what of threats from "legitimate" browsers that abuse JIT priviledges? Or vendors that drag their heels in responding to security issues?
No OS vendor wants third parties exposing users to risks it feels helpless to mitigate. Removing browsers from user's devices is an existing option, but would be a drastic step that raises serious governance questions about the power Apple wields (and on whose behalf).
As middle-ground policy options go, Apple is far from helpless.
It has already created a bright line between browsers and other apps that embed WebViews, thanks to the Browser Entitlement, and could continue to require the latter use Apple's system-provided WebKit.
For browsers slow to fix security bugs, there also options short of dissalowing other engines and their JITs. Every engine on the market today also contains a non-JITing mode. Apple could require that vendors submit both JITful and JITless builds for each version they wish to publish and could, as a matter of policy and with warning, update user devices with non-JITing versions of these browsers should users be opened to widespread attack through vendor negligence.
In the process of opening up the necessary private APIs to build truly competitive browsers, Apple can set design quality standards. For example, if Apple's engine uses a now-private mechanism to ensure that code pages are not both writeable and executable, it could require other engines adopt the same techniques. Apple could further compel vendors to aggressively adopt protections from new hardware capabilities (e.g. Control Flow Integrity (pdf)) as it releases them.
Lastly, Apple can mandate all code loaded into sandboxed renderer processes be published as open source, along with build configurations, so that Apple can verify the supply chain integrity of browsers granted these capabilities.
Apple can maintain protections for users in the face of competition. Hiding behind security concerns to deny its users access to better, safer, faster browsers is indefensible.
A final argument made by others, (but not by Apple who surely knows better), is that:
Diversity in browser engines is desirable because, without competition, there is little reason for engines to keep improving.
Apple's restrictions on iOS ensure that a heavily-used engine has a different codebase to the growing use of Blink/Chromium in other browsers.
Therefore, Apple's policies are — despite their clear restrictions on engine choice — promoting the cause of engine diversity.
This is a slap-dash line of reasoning along several axes.
First, it fails to account for the different sorts of diversity that are possible within the browser ecosystem. Over the years, developers have suffered mightily under the thumb of entirely unwanted engine diversity in the form of trailing-edge browsers; most notably Internet Explorer 6.
The point of diversity and competition is to propel the leading edge forward by allowing multiple teams to explore alternative approaches to common problems. Competition at the frontier enables the market and competitive spirits to push innovation forward. What isn't beneficial is unused diversity potential. That is, browsers occupying market share but failing to meaningfully advance the state of the art.
The solution to this sort of deadweight diversity has been market pressure. Should a browser fall far enough behind, and for long enough, developers will begin to suggest (and eventually require) users to adopt more modern options to access their services at the highest fidelity.
This is a beneficial market mechanism (despite its unseemly aspects) because it creates pressure on browsers to keep pace with user and developer needs. The threat of developers encouraging users to "vote with their feet" also helps ensure that no party can set a hard cap on the web's capabilities over time. This is essential to ensure that oligopolists cannot weaponise a feature gap to tax all software.
Taxation of software occurs through re-privatisation of low-level, standards-based features and APIs. By restricting use of previously-free features (e.g. Bluetooth, USB, Serial, MIDI, and HID) to proprietary frameworks and distribution channels, a successful would-be monopolist can extract outsized rents on any application that requires even one of these features. Impoverishing the commons through delay and obstruction is, over time, indistinguishable from active demolition.
Apple's playbook is in line with this diagnosis, preserving the commons as a historical curiosity at best. Having blockaded every road to upgrading the web, Apple have made it impossible for an open platform to keep pace with Apple's own modern-but-proprietary options. The game's simple once pointed out, but hard to see at first because it depends on consistent inaction.
This sort deadweight loss is hard to spot over short time horizons. Disallowing competitive engines may have been accidental at introduction of iOS, but its value to Apple now cannot be overstated. After all, it's hard to extract ruinous taxes on a restive population with straightforward emigration options. No wonder Cupertino continues to put on new showings of the "web apps are a credible alternative on iOS!" pantomime.
In this understanding, the web helps maintain a fair market for software services. Web standards and open source web engines combine to create an interoperable commons across closed operating systems. This commons allows services to be built without taxation; but only to the extent it's capable enough to meet user and developer needs over time.
Continuous integration of previouly-proprietary features into the commons is the mechanism by which progress is delivered. Push notifications may have been shiny in 2011 but, a decade later, there's no reason to think that a developer should pay an ongoing tax for a feature that is offered by every major OS and device. The same goes for access to a phone's menagerie of sensors, or more efficient codecs.
The sorts of diversity we have come to value in the web ecosystem exist exclusively at the leading edge.
Intense disputes about the best ways to standardise a use-case or feature are a strong sign of a healthy dynamic. It's rancid, however, when a single vendor can prevent progress across a wide swathe of domains that are critical to delivering better experiences, and suffer no market consequence.
Apple has cut the fuel lines of progress by requiring use of WebKit in every iOS browser; choice without competition, distinction without difference.
Yet this sort of participation-prize diversity is exactly what purported defenders of Apple's policies would have us believe is healthy for the web.
It's a curious argument.
In the first instance, it admits that Apple's engine is deeply sub-par, failing to achieve the level of quality that even Mozilla's investments have produced. Having given up the core claim of product superiority, this failure is rhetorically pivoted into a defense of the ongoing failure to compete: because Apple's product is bad, it shouldn't be forced to allow competition, as people might then choose better products.[5]
Apple is not lacking funds or talent to build a competitive product, it simply chooses not to. Apple's 2+ trillion dollar market cap is paired with nearly $200 billion in cash on hand. One could produce a competitive browser for the spare change in Cupertino's Eames lounges.
Claims that foot-dragging must be protected because otherwise capable engines might win share is not much of a defence. Excusing poor performance is to suggest that Apple does not possess the talent, skill, and resources to ever construct a competitive engine. I, at least, think better of Apple's engineering acumen than these nominal defenders.
Would WebKit really dissapear if Apple were to allow other engines onto iOS? We have a natural experiment in Safari for macOS. It continues to enjoy a high share of that browser market despite stiff and competition from browsers that include higher-quality engines. Why are Apple's defenders so certain that this won't be the result for iOS?
And what is the worst-case scenario, exactly?
That Safari loses share such that Apple must respond by funding the WebKit team adequately? That the Safari team feels compelled to switch to another open source rendering engine (e.g. Gecko or Blink), preserving their ability to fork down the road, just as they did with KHTML, and as the Blink project did with WebKit?
None of these are close ended scenarios, nor must they result in a reduction in constructive, leading edge diversity. Edge, Brave, Opera, and Samsung Internet consistently innovate on privacy and other features without creating undue drag on core developer interests. Should the Chromium project become an unwelcome host for this sort of work, all of these organisations can credibly consider a fork, adding another new branch to the lineage of browser engines.
It's not a foregone conclusion the world's most valuable tech firm must produce the lowest-quality browser and externalise huge costs onto developers and users. Developer's might even take Apple's side if coercion about engine choice weren't paired with failure to keep pace on even basic features.
The point of diversity at the leading edge is progress through competition. The point of diversity amid laggards is the freedom to replace them — that's the market at work.
Apple's polices against browser choice were, at some point, relatively well grounded in the low resource limits of early smartphones. But those days are long gone. Sadly, the legacy of a closed choice, back when WebKit was still a leader in many areas, is an industry-wide hangover. We accepted a bad deal because the situation seemed convivial, and ignored those who warned it was a portent of a more closed, more extractive future for software.
Only if we had listened.
Thanks to Chris Palmer and Eric Lawrence for their thoughtful comments on drafts of this post. Thanks also to Frances for putting up with me writing this post on holiday.
As we shall see, it would be better for Apple if their "supporters" would stop inventing straw man arguments as they tend to undermine, rather than bolster, Cupertino's side. ↩︎
Browser engines all have a form of selective exclusion of code that is technically available within the codebase but, for one reason or another, is disabled in a particular environment. These switches are known variously as "flags," "command line switches," or "runtime-enabled features."
New features that are not ready for prime time may be developed for months "behind a flag" and only selectively enabled for small populations of developers or users before being made available to all by default. Many mechanisms have existed for controlling the availability of features guarded by flags. Still, the key thing to know is that not all code in a browser engine's source repository represents features that web developers can use. Only the set that is flagged on by default can affect the programmable surface that web developers experience.
The ability of the eventual producer of a binary to enable some flags but not others means that even if an open source project does agree to include code for a feature, restrictions on engine binaries can preclude an alternative browser's ability to provide even some features which are part of the code the system binary could include.
Flags, and Apple's policies towards them over the years, are enough of a reason to reject Apple's feint towards open source as an outlet for unmet web developer needs on iOS. ↩︎
It's perverse that the wealthy users Apple sells its powerful devices to — the very folks who can most easily dedicate the extra CPU and RAM necessary to enable multiple layers of protection — are prevented from doing so by Apple's policies that are, ostensibly, designed to improve security. ↩︎
JIT and sandbox creation are technically separate concerns (and could be managed by policy independently), but insofar as folks impute a reason to Apple for allowing its engine to use this technique, sandboxing is often offered as a reason. ↩︎
A very strange sub-species of the "Apple shouldn't be made to allow competition becuse it's product is bad" argument suggests that Google might ask users to install Chrome if engine choice becomes possible. This reads to me like a case of un-updated priors. Recall that until late 2020, it wasn't possible for any browser to be the iOS default but Safari.
It has only been in the past year that iOS has allowed browser competition at all, but already, this regulatory-scrutiny-derived changed has led to more aggressive advertising for other browser prodcuts, even though they're still forced to use Apple's shoddy engine.
This is largely because of the way browsers monetise. Once a browser is your default, it is more likely that you will perform searches through it, which gets the browser maker paid. The new status quo means that the profit maximising reason to suggest that users switch is already in place. What's left is the residual of consistently broken and missing features that raise costs for all developers due to Apple's neglect.
In other words, the bad thing that these folks assume will happen has already happened, and all that's left to defend is the indefensible. ↩︎




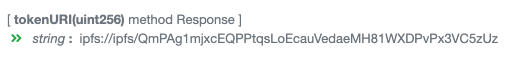






{kind=link}